PRT Dateien / PRT-Dateiformat
Einleitung
Die Kommunikationsprotokolle der meisten Hardware-Geräte, ob seriell oder per Netzwerk angeschlossen, sind proprietär und nicht standardisiert.
Ein PRT Protokoll ist eine Textdatei, die es ermöglicht über die RS232- oder TCP/IP oder UDP-Schnittstelle eine Verbindung mit dem am PC oder einem am Netzwerkswitch angeschlossenen Gerät aufzubauen.
Das Dateiformat PRT wurde speziell entwickelt, um in NRN zu spezifizieren, welche Arten von technischen Kommandos über das Netzwerk mit den Geräten ausgetauscht werden können. Diese Kommandos (Aktionen und Ereignisse) werden als ASCII-Strings hin und her gesendet.
Verwendung von PRTs in NRN
Siehe Reiter Geräteprotokolle)
Anlegen von PRTs
PRT-Dateien können im Setup-Modul im Reiter Geräteprotokolle definiert werden:
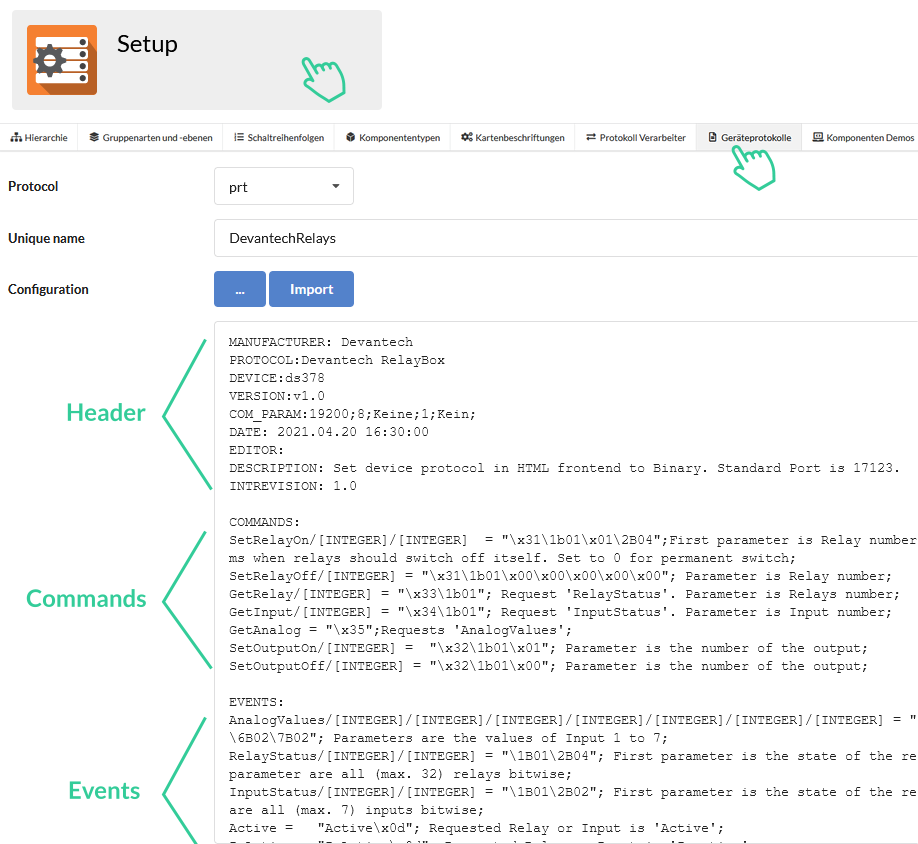
Bis auf den "Header" mit Steueranweisungen (bisher nur für serielle Geräte) sind die COMMANDS und EVENTS natürlich das Entscheidende. Dieser "Header" sei momentan hier nur kurz erwähnt.
Prinzipiell gibt es "Key: Value" Zeilen, wobei die insgesamt beliebig sind und nur wenige fest verwendet werden, um bspw. einen "Protokollnamen" generieren zu können.
Beim Header sind Semikolons am Zeilenende optional - sonst aber notwendig (aus historischen Gründen).
Kommentare können durch "//" für den Rest der Zeile hinzugefügt werden.
Die Blöcke "COMMANDS:" und "EVENTS:" werden genau durch diese jeweilige Überschrift eingeleitet. In den darauffolgenden Zeilen wird die iSy+ Syntax (iSMaster):
COMMAND/[PARAMETERTYP]/.../[PARAMETERTYP]
bzw.
EVENT/[PARAMETERTYP]/.../[PARAMETERTYP]
mit Ascii- oder Hexdaten (den Bytes, die verschickt oder empfangen werden) verknüpft. Bei COMMAND wird definiert, wie die Parameter in die Daten eingefügt werden, bei EVENT entsprechend wie sie daraus extrahiert werden. In der Implementierung für NeuroomNet werden natürlich nicht iSMaster-Kommandos/Ereignisse benutzt, sondern NeuroomNet-Aktionen und -Ereignisse (es gibt keinen Unterschied im Format der Datei, nur in der internen Verarbeitung).
Daten können nur dann als Hexdaten definiert werden, wenn sie konstant sind (also keine Parameter verwendet werden), z. B.:
PowerOn = 0x506f7765724f6e;
PowerOff = 0x506f7765724f6666;
Groß-/Kleinschreibung sollte egal sein.
Dieser Stand war damals der Ausgangspunkt für die Weiterentwicklung.
Asciidaten hingegen müssen verwendet werden, wenn es Parameter gibt. Sie sollten mit Anführungszeichen umschlossen werden. Genau genommen ist es so, dass einfach nur das erste und das letzte Zeichen gleich sein müssen. Das war ursprünglich dafür gedacht, dass "Quotes" auch im String ohne Kennzeichnung (Escape) vorkommen können. Vielleicht liest sich das dann besser. Tatsächlich müssen Quotes aber auch innerhalb von Anführungszeichen nicht besonders behandelt werden (Anfang und Ende werden bei Gleichheit einfach entfernt).
Auch in Asciidaten kann man willkürliche Zeichen eingeben, die dann mit "\x" eingeleitet werden und hexadezimal kodiert sein müssen. Das muss dann immer nur genau ein Zeichen sein. Obiges Beispiel ist im Ergebnis identisch zu diesem:
PowerOn = "\x50\x6f\x77\x65\x72\x4f\x6e";
PowerOff = "\x50\x6f\x77\x65\x72\x4f\x66\x66";
"\x" kann deshalb nicht so gesendet werden. Stattdessen müsste man mindestens für "\" den Ascii-Code (0x5c) verwenden und es somit als "\x5c" angeben. Das war bisher aber noch nie notwendig.
Parameter werden aus dem Masterkommando durch Aufteilung an den "/" bestimmt. Auch NeuroomNet benutzt Parameter in analoger Weise.
Unterstützt werden [STRING] und [INTEGER]. Im iSCom gab es zwar rudimentäre Implementierungen für [FLOAT] und [BOOL], die auch in die Javascript-Implementierung eingegangen und dabei verbessert worden sind. Allerdings sind sie in beiden Fällen nie produktiv verwendet worden und somit auch nur wenig getestet. Es gab über die Jahre bisher auch nie Bedarf dafür. Deshalb werden die beiden Fälle im folgenden zurzeit noch ausgespart.
Die Parameter werden von links nach rechts ab 1 gezählt. In NeuroomNet heißen sie dann auch "p1", usw.
Jeder Parameter darf in den Asciidaten nur einmal verwendet werden. Das ist in den allermeisten Fällen sicher ausreichend. Falls nicht, würde man der Kommandodefinition einfach einen zusätzlichen Parameter geben und im Master oder NeuroomNet dafür sorgen, dass zweimal der selbe Wert genutzt wird.
Auf die Parameter bezieht man sich dann mit "\<nr>" - für die literale Verwendung von "\1" etc. gilt das selbe wie für "\x" oben. Da nach Schema die Parameternummer einstellig sein muss, sind derzeit nicht mehr als 10 Parameter möglich, wobei "\0" dem 10. entspricht. Mehr als 4-5 Parameter wurden bisher auch nie benötigt.
Dem "\<nr>" folgt eine Formatangabe. Diese kann sein:
- a für ascii
- b für binär, little endian
- B für binär, big endian
- h für hexascii, little endian
- H für hexascii, big endian
Es gab auch mal "x" für "hexascii hexascii" (doppelt) - das wäre bisher für ein einziges exotisches Protokoll hilfreich gewesen, wurde aber nachträglich entwickelt und deshalb nie eingesetzt und auch nicht produktiv getestet (- Das nur als Kommentar für den Teil im Quellcode).
Im iSCom wurde mehr oder weniger erzwungen, dass die Parameter im Master und in der Übersetzung in der selben Reihenfolge (letztlich also aufsteigend nummeriert) verwendet werden. In der neuen Implementierung kann man sie aber auch vertauschen. Das mag nur für spezielle Anwendungen notwendig sein, bspw. wenn man einen Bug in einer Firmware nur im Protokoll ohne Änderungen am Masterscript/NeuroomNet beheben möchte.
Für [STRING] ist nur das Format "a" zulässig, für [INTEGER] werden alle unterstützt.
Nach der Formatangabe kommt eine Länge in Byte (theoretisch bis 255, da die Länge nicht nur Byte angibt, sondern auch selbst nur ein Byte ist).
Das mag u. U. etwas verwirrend sein und vielleicht gibt es auch bessere Lösungen. Man lernt ja in 14 Jahren auch dazu ...
Der Punkt ist nämlich, dass binär bspw. eine 128 mit \1b01 kodiert würde, während für hexascii auch \1h01 richtig wäre, aber als "80" (2 Bytes) ausgegeben würde. \1h02 hätte "8000" zur Folge (und \1H02 "0080").
Beim Senden gilt Folgendes
Bei der Formatangabe 'a' ist die Längenangabe 0 möglich, sonst nicht. 0 bedeutet dann "automatisch": 1:1 und so viel wie notwendig.
Ist die Längenangabe bei Strings größer als 0, wird links mit Leerzeichen aufgefüllt. Bei Zahlen werden entsprechend der Länge '0'en davor gesetzt.
'b' und 'B' bzw 'h' und 'H' unterscheiden sich natürlich nur, wenn die Länge größer als 1 ist. In diesen Fällen wird mit binären 0en oder "00" rechts bzw. links aufgefüllt.
Falls die angegebene Länge nicht möglich ist (, weil also bspw. 256 nicht in \1b01 passt), sollte es einen Laufzeitfehler geben beim Verschicken. Was man damit macht, wäre noch zu klären. So wird es beim direkten Versenden sicherlich im "Toast" angezeigt, was aber passiert innerhalb der Mediensteuerung?!
Für das Empfangen gilt
Ein Ascii-String sollte ähnlich wie ein Regex (regulärer Ausdruck) betrachtet werden (ist tatsächlich auch so implementiert) - hier als einfaches Muster, das intern umgesetzt wird.
Damit muss die Längenangabe 00 in jedem Fall durch Begrenzer (ggf. auch Anfang und/oder Ende) mit Sinn gefüllt werden. Längen größer 0 werden in der entsprechenden Größe verwendet. Sind die Längen der Parameter im Protokoll auf endliche Werte festgelegt, kann man mit Längen und/oder Begrenzern arbeiten (z. B. bei Extron mit "*").
In vielen Fällen wird bei "fehlerhaft" definierten Asciidaten (, wenn also z. B. Längen und Begrenzer keine Erkennung erlauben, ) einfach kein Ereignis ausgelöst. Die Daten werden verworfen. Wenn aber z. B. nach der Erkennung ein Datenteil nicht in eine Zahl gewandelt werden kann (weil dem Muster entsprechend Text gelesen wurde), so wird intern eine TypeError-Exception ausgelöst. Was damit irgendwann mal passiert (am einfachsten ignoriert oder gelog't) muss evtl. noch geklärt werden.
Weitere Protokoll Bestandteile sind
TOX: <zahl>
Verzögerung in Millisekunden beim Senden, um Endgeräte nicht mit zu vielen Kommandos zu überfluten - noch nicht implementiert!
ETX: <hex- oder ascii-string>
End-of-Text zur Separierung von Datenpaketen - bei UDP nicht notwendig
STX: <hex- oder ascii-string>
Start-of-Text zur Separierung von Datenpaketen - bei UDP nicht notwendig
STX und ETX können je nach Protokoll auch gemeinsam vorkommen. Hier kann sogar ein String wie 0x0d0a oder "\x0d\x0a" verwendet werden. Zu beachten ist, dass besonders aus historischen Gründen, aber auch aus Gründen der Flexibilität, diese Angaben nicht vor bzw. nach den zu sendenden Daten zusätzlich verschickt werden. In den COMMANDS muss das also explizit angegeben werden.
Hier gibt es zurzeit eine beabsichtigte Inkompatibilität zum iSCom: Dort darf STX/ETX nicht in der Übersetzung der EVENTS enthalten sein. Hier muss es dabei stehen. Das soll für bessere Konsistenz (mit COMMANDS) und Lesbarkeit/Vergleich (mit Protokolldefinitionen) sorgen!
Die Angaben STX/ETX dienen also ausschließlich der Konfiguration der Trennung der Datenpakete.
TOR: <zahl>
Timeout beim Empfang - besonders ohne STX und ETX oder nur mit STX wird nach der in Millisekunden angegebenen Zeit ohne empfangene Daten(!) das bis dahin gesammelte Datenpaket an den Parser übergeben.
Bei UDP ist das wieder nicht notwendig (weil immer komplette Datenpakete einzeln übertragen werden).
An die Definition von COMMANDS und EVENTS kann hinter dem ";" ein erklärender Text (Hilfe) hinzugefügt sein, der auch mit ";" abgeschlossen sein muss, aber selber keines enthalten darf. Sonst können schlimme Dinge passieren ;-)
Vorgaben Header
- MANUFACTURER: BrightSign - Hersteller des Gerät
- PROTOCOL: NeuroomNetUDP - Protokoll Name
- DEVICE: BrightSignPlayer - Gerätebezeichnung
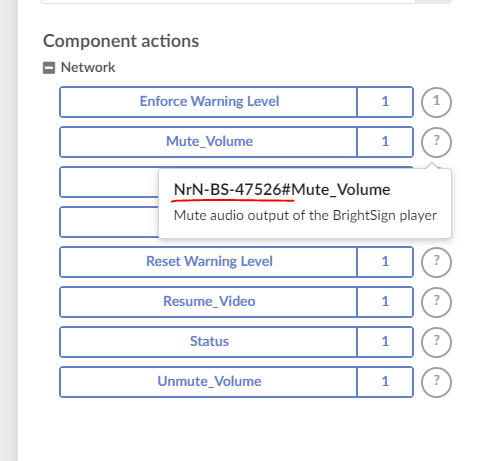
- UNIQUEID: NrN-BS-47526 - Optimalerweise Kürzel mit Zufallskomponente,
- VERSION: v0.1 - Version der PRT Datei
- COM_PARAM: 115200;8;No;1;No; - muss vorhanden sein, auch bei UDP
- DATE: 2022.03.08 12:00:00 - Jahr, Monat, Tag und Uhrzeit der Erstellung
- EDITOR: inSynergie - Ersteller(Firma) der PRT Datei
- DESCRIPTION: Standard BrightSign UDP protocol for NeuroomNet
- INTREVISION: 1.0 - Immer 1.0
Hinweise zur Unique ID
Ist diese NICHT vorhanden wird JEDE Änderung an der Datei als inkompatibel gewertet und ALLE vorhandenen Referenzen (Aktionen/Ereignisse) UNGÜLTIG.
Damit keine Dopplungen und Verwirrungen bei den Aktionen auftauchen, sollen die Unique IDs eine Zufallkomponente enthalen (z.B. ein Hash-Wert der Datei oder ein Ausschnitt der Erstellungszeit in Millisekunden).
Die Unique ID sollte nicht länger als 10-15 Zeichen sein, damit sie an anderen Stellen (Aktionen der Komponenten) korrekt dargestellt werden kann.
Die Unique ID und somit das verwendete PRT Protokoll einer Komponente kann in den Aktionen auch in der Description eingesehen werden: